The main intro is the presentation I published initialy.
Steve's post,
Thank for the Memory, a recent discussion about easy access to documents on the Net and one of the traditional
predictions for the New Year driven a
special interestof mine to surface.
It would be nice to collect your opinions on the subject. First of all, read
Steve's post. I think that what allowed the connexion of the two subjects was :
The issue though, is not the amount of memory, but the need for massive and dynamic interconnect..
Now, a small historic of the elements that made me predict the building of what I named the Semantic Internet.
While following Steve Jobs keynote presenting
Spotlight, a tool included in the next Mac OS X edition, Tiger. Spotlight's subtitle is "Find Anything, Anywhere Fast". I show applications for my job immediately, for building assistants based on this. What was a little bit tricky was the
anywhere. I never considered my hard disk to be everywhere. What would be nice would be to really search
everywhere, at least where shared resources are available.
In early 2003, with a few friends, we experimented the shared resources trough Apple's iDisks, a distant storage space, featuring a public space and password protected sections. That's a great way to share documents and each iDisk's index allow for fast searching, not as efficient as Spotlight should do, but good enough for us.
Some time after the presentation of Spotlight, Google announced the
Google Desktop Search and I show Light ! ;-) What if...
- The desktop search tool creates an index pointing to every available document, including those available in the "Shared documents" folder, then send to a central facility the subset concerning the shared ones.
- Every index collected is compiled in a database conserving the accession data (probably a serial of the software rather then an IP, to be able to adjust to mobility),
- then make this database available for searching via a simple interface, as Spotlight's or Google's
That means that a search would go through every available and shared document over the Net. Whaou!
Is that possible, interesting, economically sustainable, culturally acceptable and what would be the applications?
Possible
It seems so. Shared documents could be identified by
DOIs [Digital Objects Identifiers] or something equivalent and tracked the same way as
BitTorrent made usual.
Economically sustainable
As much as
Google actually, as the same business model could apply, maybe combined with a "larger"
Flickr-like service including sharing of every kind of document.
Computers are cheaper and cheaper, you can even get a
Macintosh for $500 [o_O]
More and more people is connected via high-speed services, and stay connected permanently.
One point that is so obvious that it seems hidden, is that this is distributed computing! Each computer being charged with the creation of the index of the Shared Content, a task that would be to onerous to be carried out by a central facility.
culturally acceptable
As much as
Lawrence Lessig describes it
here, with people used to
BitTorrent,
Flickr,
Common Content,
Open Access,
PLoS etc.
And Ideas would
fly around as they actually do in blogs.
Interesting
I skipped this one to put it near the
applications. While dreaming about the way to use Spotlight I imagined a fully linked text application for "intelligent" reading of scientific papers, automatically linking every relevant document to keywords spotted by the reader and constituting an aliases collection within the document. Imagine yourself in front of a review paper tagged this way, intellectual heaven :-)
For the moment I use an Applescript that transforms the selected word to a Google Search :
http://www.google.com/search?q=keyword&ie=UTF-8&oe=UTF-8
or
http://scholar.google.com/scholar?q=keyword&ie=UTF-8&oe=UTF-8&hl=en&btnG=Search. That could be made automatically for every document, and include pertinent Shared Documents.
What do you think of it ?
Now, the second level would be to consider what you can build with such a facility: feeds. Aggregated content following your thoughts. If you have the right keywords, you may be willing to get new material as is made available, either as a notification (via an RSS reader or an e-mail alert) or even by direct download to a specified folder, limiting to some files formats virus free [this isn't paranoia, just protection].
Then you may be willing to share your feeds with other people as you can do already with
Bloglines, distributing collections of links to pertinent documents covering some topic on which you have expertise, including your stuff, maybe some kind of review of the domain. That is for loops :-)
There are two elements I would like to see added.
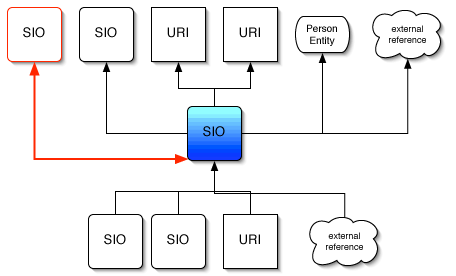
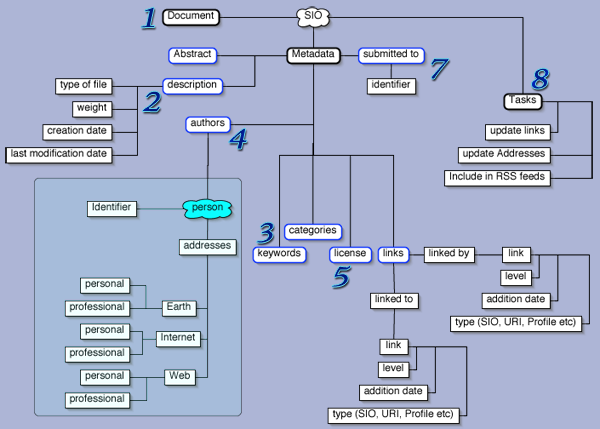
First, the possibility to add keywords and abstract describing the document itself; probably using something like
RDF, to be accessible for machines. Second, the possibility, not obligation, to sign in when you
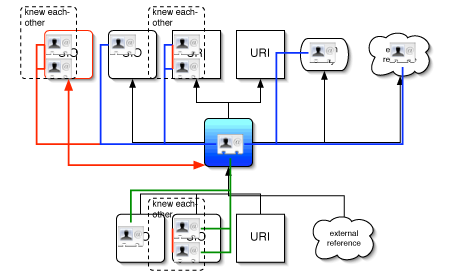
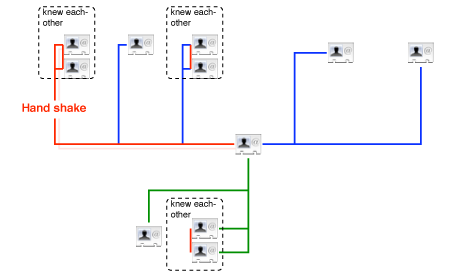
use one of the shared documents, in order to start building a web of awareness and bonds between the users of the system, something like the
FOAF but rather named UOYR : User Of Your Ressource, or something like that.
The
Semantic Internet would be born.
Do you see the parallel with Jeff Hawkins' model of the human brain ?
Memories : documents
Meta-memories : RSS feed for DOI collections
Interconnexion : the Net, it was build for that after all
Loops : Feeds of Feeds of ...
my addition: Specialized Neural Centers : UOYR webs
Now, as I said elsewhere,
if my guess is wrong and Google, Apple, Yahoo! or whoever else aren't heading this way,
someone should start working on that. As soon as possible. A year is a short lapse of time and I would like to see my prediction being realized.
There is a final consequence I would like to present for discussion.
Most experts are connected people. And they could decide to include on their Shared Documents Folder some reviews on specific terms, the same way they would write an encyclopedia entry. And tag it with a special tag, say Interpedia [for
Internet Encyclopedia].
That would be one kind of an encyclopedia I would like to have handy :-)
Please, comment abundantly. And somebody have to print that and stick it
there. I would like to here from those people at Redwood. Steve say that is
a fine place for a brain spa... I do need something like that.
To keep the format closer to what a blog support, without being difficult to follow, I will split the subject in small portions each representing one aspect.
Syntheses will be proposed as documents "attached" to the blog, and as blog entries all of them dated 1st january 2005, as it is one of my predictions for 2005.
is set for a glossary.
 by-nc-sa
by-nc-sa